目录
1 Min-Max归一化
方法1:自定义的Min-Max归一化封装函数
方法2: scikit-learn库中的MinMaxScaler
2 Z-score归一化
方法1:自定义的Z-score归一化封装函数
方法2: scikit-learn库中的StandardScaler
3 最大值归一化
4 L1归一化
方法1:自定义的Z-score归一化封装函数
方法2: scikit-learn库中的Normalizer
5 L2归一化
方法1:自定义的L2归一化归一化封装函数
方法2: scikit-learn库中的Normalizer
6 Box-Cox归一化
方法1:自定义的L2归一化归一化封装函数
方法2: scipy库的boxcox
7 选择哪种归一化
实验数据:链接:https://pan.baidu.com/s/1yT1ct_ZM5uFLgcYsaBxnHg?pwd=czum 提取码:czum
实验数据介绍:参考文章1.2节(数据介绍链接)
1 Min-Max归一化
最小-最大归一化(Min-Max Normalization)是一种将数据缩放到特定范围内的线性变换方法,通常是[0, 1]。这种方法保证了数据的最小值被映射为0,最大值被映射为1,中间的值则按比例进行缩放。
最小-最大归一化的公式为:
![]()
其中,![]() 是归一化后的值,x 是原始数据点,max(x) 和 min(x) 分别是数据集中的最大值和最小值。
是归一化后的值,x 是原始数据点,max(x) 和 min(x) 分别是数据集中的最大值和最小值。
示例程序将使用两种方法实现,自定义的最小-最大归一化封装函数,并使用scikit-learn库中的MinMaxScaler类作为第二种方法来实现归一化。以下是具体的实现:
方法1:自定义的Min-Max归一化封装函数
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 定义最小-最大归一化函数,使其能够处理DataFrame或Series
def min_max_normalization(data):
# 检查数据是否为pandas Series或DataFrame
if isinstance(data, pd.Series):
# 如果是Series,直接应用归一化
min_val = data.min()
max_val = data.max()
data_normalized = (data - min_val) / (max_val - min_val)
return data_normalized
elif isinstance(data, pd.DataFrame):
# 如果是DataFrame,逐列应用归一化
return (data - data.min()) / (data.max() - data.min())
else:
raise ValueError("Input data must be a pandas Series or DataFrame")
# 方法一:使用自定义函数进行归一化
data_normalized_custom = min_max_normalization(data['Total_Spending'])方法2: scikit-learn库中的MinMaxScaler
from sklearn.preprocessing import MinMaxScaler
# 方法二:使用 scikit-learn 的 MinMaxScaler 进行归一化
scaler = MinMaxScaler()
data_normalized_sklearn = scaler.fit_transform(data[['Total_Spending']])
plt.figure(figsize=(14, 5))
# 绘制原始数据和归一化数据的对比图
plt.subplot(1, 2, 1)
# 绘制原始数据的线条图
plt.plot(data['Total_Spending'], marker='o')
plt.title('Original Data')
plt.xlabel('Index')
plt.ylabel('Value')
plt.subplot(1, 2, 2)
# 绘制自定义归一化方法的数据的线条图
plt.plot(data_normalized_custom, label='Normalized (Custom)', linestyle='--', marker='x')
# 绘制 scikit-learn 归一化方法的数据的线条图
plt.plot(data_normalized_sklearn, label='Normalized (scikit-learn)', linestyle='-.', marker='s')
# 添加图例、标题和坐标轴标签
# plt.legend(loc='upper center')
plt.title('min_max_normalization')
plt.xlabel('Index')
plt.ylabel('Value')
运行结果如下:
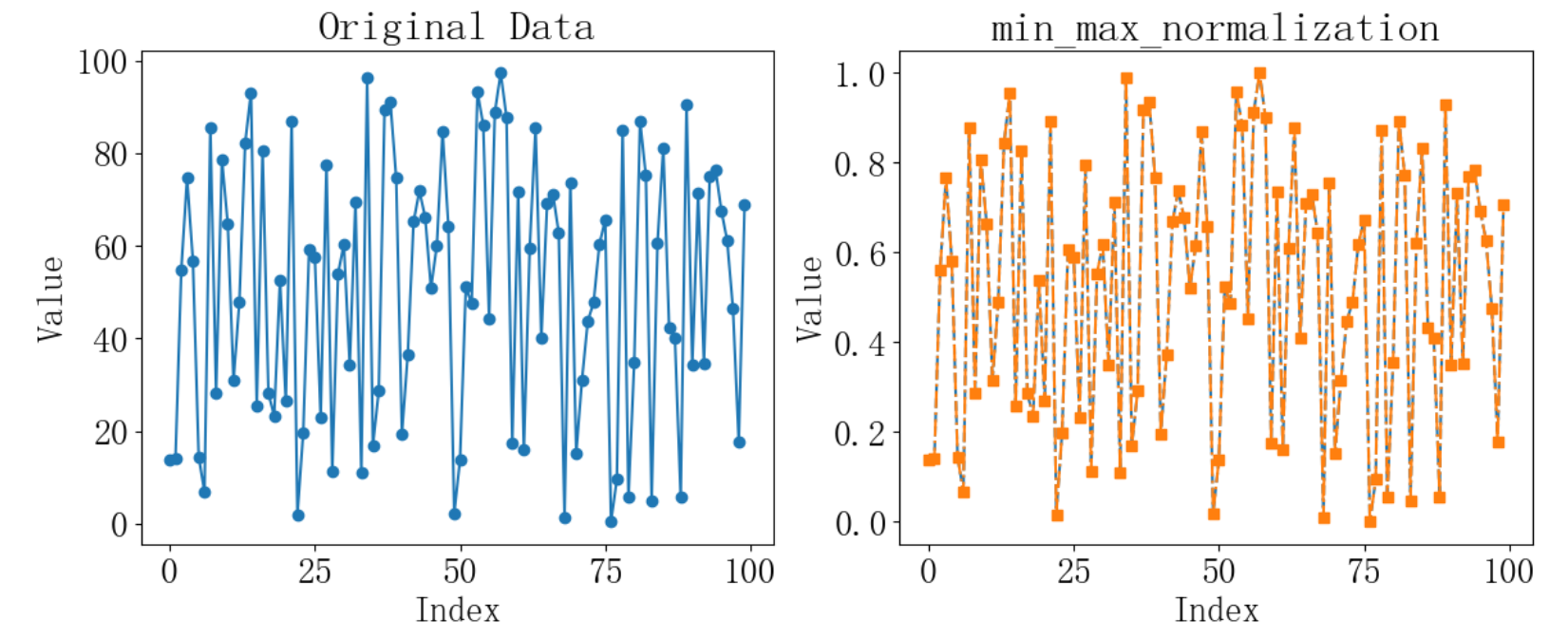
2 Z-score归一化
Z-score归一化,也称为标准化(Standardization),是一种将数据按比例缩放至特定均值(mean)和标准差(standard deviation)的方法。其目的是将数据转换为一个标准分布,其中数据的均值为0,标准差为1。Z-score归一化它确保了不同特征具有相同的尺度和分布特性。
示例程序将使用两种方法实现,自定义的最小-最大归一化封装函数,并使用scikit-learn库中的StandardScaler类作为第二种方法来实现归一化。以下是具体的实现:
方法1:自定义的Z-score归一化封装函数
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 使用自定义函数进行Z-score归一化
def z_score_normalization(data):
if isinstance(data, (pd.Series, pd.DataFrame)):
mean = data.mean()
std = data.std()
data_normalized = (data - mean) / std
return data_normalized
else:
raise ValueError("Input data must be a pandas Series or DataFrame")
# 使用自定义函数进行Z-score归一化
data_normalized_custom = z_score_normalization(data.iloc[:, 7:10])方法2: scikit-learn库中的StandardScaler
from sklearn.preprocessing import StandardScaler
# 使用 scikit-learn 的 StandardScaler 进行Z-score归一化
scaler = StandardScaler()
data_normalized_sklearn = scaler.fit_transform(data.iloc[:, 7:10])
data_normalized_sklearn = pd.DataFrame(data_normalized_sklearn, columns=data.columns[7:10]) 运行结果如下,选取的3个数据有不同的尺度,最后归一化到了0-1的范围: 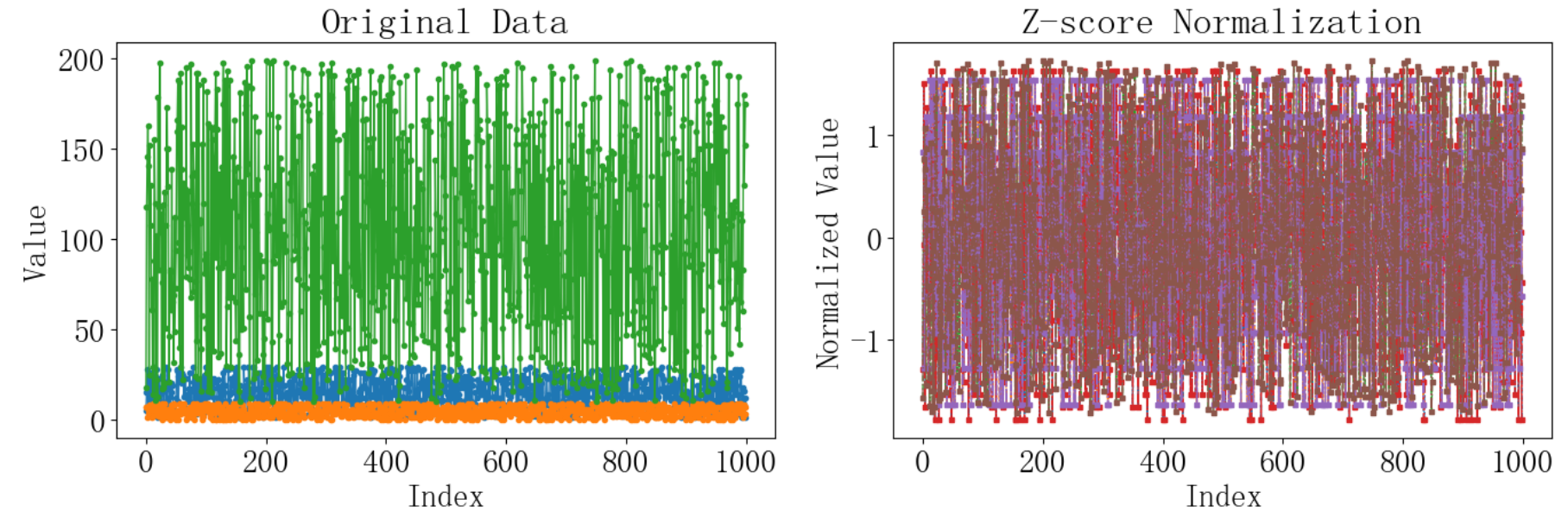
3 最大值归一化
最大最小值归一化(Min-Max Normalization)是一种线性变换,它将数据的最小值映射到0,最大值映射到1,所有其他值按比例映射到0和1之间。
最大最小值归一化的公式为:
![]()
其中:x 是原始数据点,x′ 是归一化后的数据点,min(x) 是数据中的最小值,max(x) 是数据中的最大值。
示例程序自定义的最小-最大归一化封装函数,以下是具体的实现:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 使用自定义函数进行最大最小值归一化
def min_max_normalization(data):
if isinstance(data, (pd.Series, pd.DataFrame)):
data_normalized = (data - data.min()) / (data.max() - data.min())
return data_normalized
else:
raise ValueError("Input data must be a pandas Series or DataFrame")
# 使用自定义函数进行最大最小值归一化
data_normalized_custom = min_max_normalization(data.iloc[:, 7:10])
# 绘制原始数据和归一化数据的对比图
plt.figure(figsize=(14, 5))
plt.subplot(1, 2, 1)
# 绘制原始数据的线条图,假设我们有3列数据
for idx, col in enumerate(data.columns[7:10]):
plt.plot(data.index, data[col], marker='o', linewidth=1, markersize=3)
plt.title('Original Data')
plt.xlabel('Index')
plt.ylabel('Value')
plt.subplot(1, 2, 2)
# 绘制自定义最大最小值归一化方法的数据的线条图
for idx, col in enumerate(data.columns[7:10]):
plt.plot(data.index, data_normalized_custom[col], linestyle='--', marker='x', linewidth=1, markersize=3)
# 添加图例、标题和坐标轴标签
plt.title('Min-Max Normalization')
plt.xlabel('Index')
plt.ylabel('Normalized Value')
# 显示图形
plt.tight_layout()
plt.show()运行结果如下:
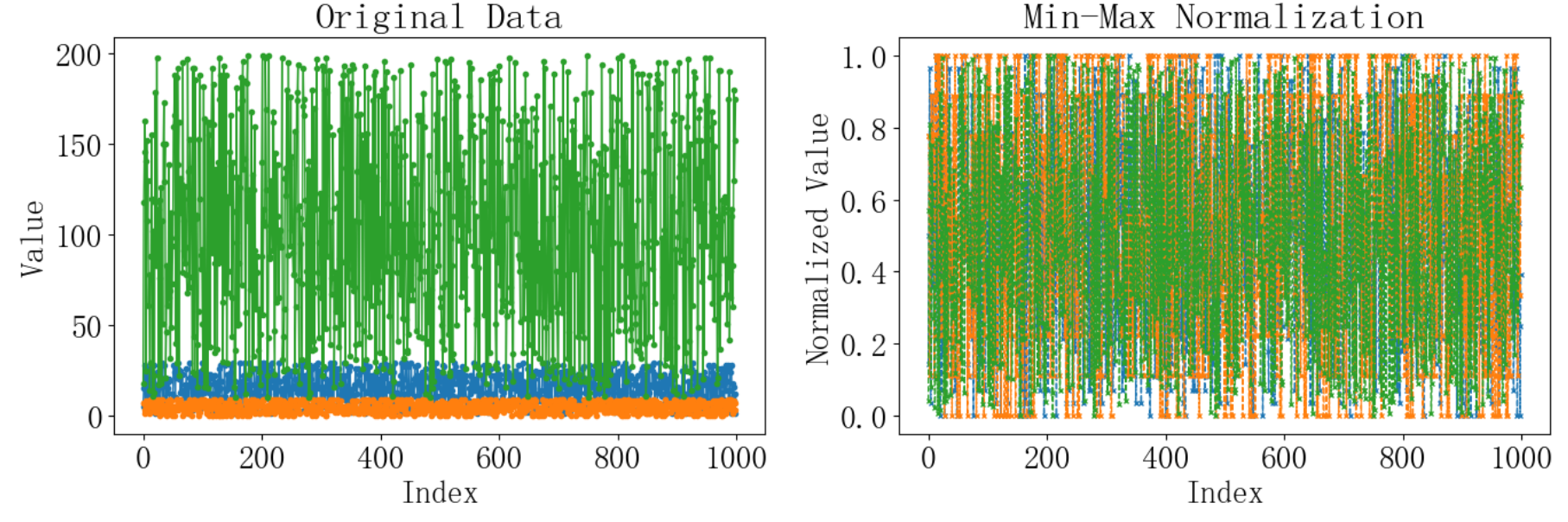
4 L1归一化
L1归一化,也称为曼哈顿距离归一化或1-范数归一化,是一种将数据的特征向量按其绝对值的总和进行归一化的方法。其目的是将每个特征的绝对值加和为1。L1归一化在某些特定的机器学习算法中很有用,比如在L1正则化(Lasso回归)中。
L1归一化的公式为:
![]()
- x 是原始数据向量。
- x′ 是归一化后的数据向量。
- ∑∣x∣ 是向量x中所有元素绝对值的总和。
L1归一化的优点包括:
- 它对异常值具有一定的鲁棒性,因为异常值不会像在L2归一化中那样对结果产生过大的影响。
- 它可以将数据转换为稀疏表示,这在某些类型的机器学习算法中是有利的。
示例程序将使用两种方法实现,自定义的L1归一化封装函数,并使用scikit-learn库中的Normalizer类作为第二种方法来实现归一化。以下是具体的实现:
方法1:自定义的Z-score归一化封装函数
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 使用自定义函数进行L1归一化
def l1_normalization(data):
if isinstance(data, pd.Series):
data = data.to_frame() # 将Series转换为DataFrame
if isinstance(data, pd.DataFrame):
norms = np.abs(data).sum(axis=1)
data_normalized = data.div(norms, axis=0)
return data_normalized
else:
raise ValueError("Input data must be a pandas Series or DataFrame")
# 使用自定义函数进行L1归一化
data_normalized_custom = l1_normalization(data.iloc[:, 7:10])方法2: scikit-learn库中的Normalizer
from sklearn.preprocessing import Normalizer
# 使用 scikit-learn 的 Normalizer 进行L1归一化
normalizer = Normalizer(norm='l1')
data_normalized_sklearn_l1 = normalizer.fit_transform(data.iloc[:, 7:10])
data_normalized_sklearn_l1 = pd.DataFrame(data_normalized_sklearn_l1, columns=data.columns[7:10])# 绘制原始数据和归一化数据的对比图
plt.figure(figsize=(14, 5))
plt.subplot(1, 2, 1)
# 绘制原始数据的线条图
for idx, col in enumerate(data.columns[7:10]):
plt.plot(data.index, data[col], label=f'Original {col}', marker='o', linewidth=1, markersize=3)
plt.title('Original Data')
plt.xlabel('Index')
plt.ylabel('Value')
plt.subplot(1, 2, 2)
# 绘制自定义L1归一化方法的数据的线条图
for idx, col in enumerate(data_normalized_custom.columns):
plt.plot(data.index, data_normalized_custom[col], linestyle='--', marker='x', linewidth=1, markersize=3)
# 绘制自定义L1归一化方法的数据的线条图
for idx, col in enumerate(data_normalized_sklearn_l1.columns):
plt.plot(data.index, data_normalized_sklearn_l1[col], linestyle='--', marker='x', linewidth=1, markersize=3)
# 添加图例、标题和坐标轴标签
plt.title('L1 Normalization')
plt.xlabel('Index')
plt.ylabel('Normalized Value')
# 显示图形
plt.tight_layout()
plt.show()运行结果如下:
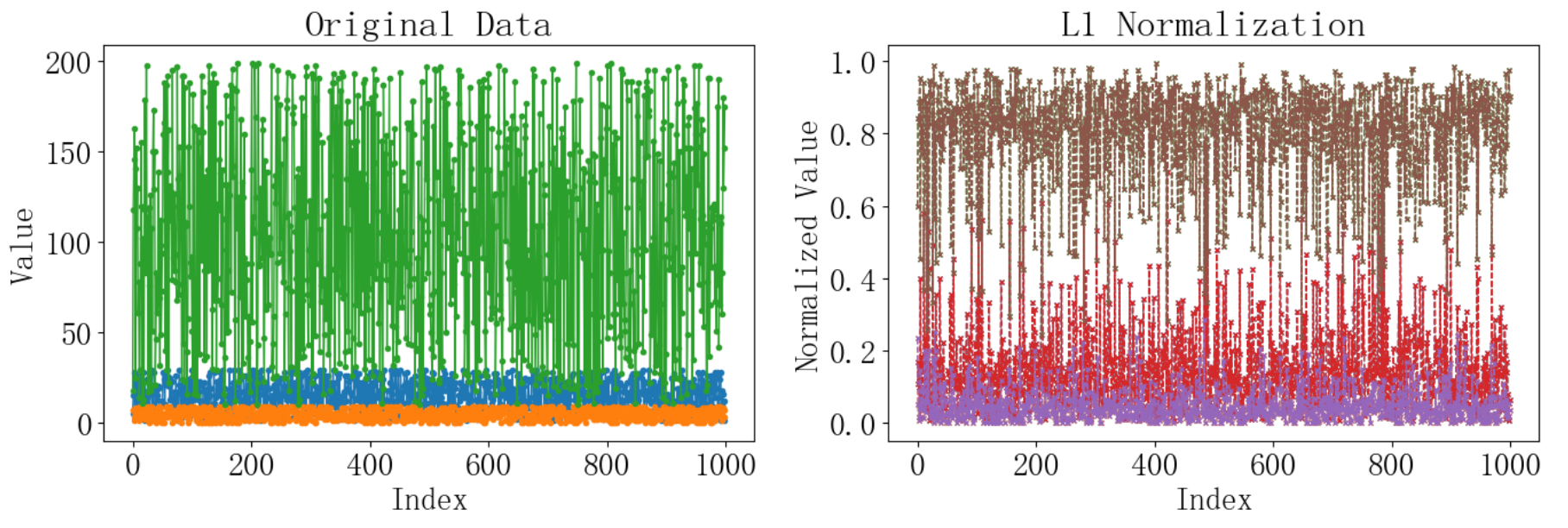
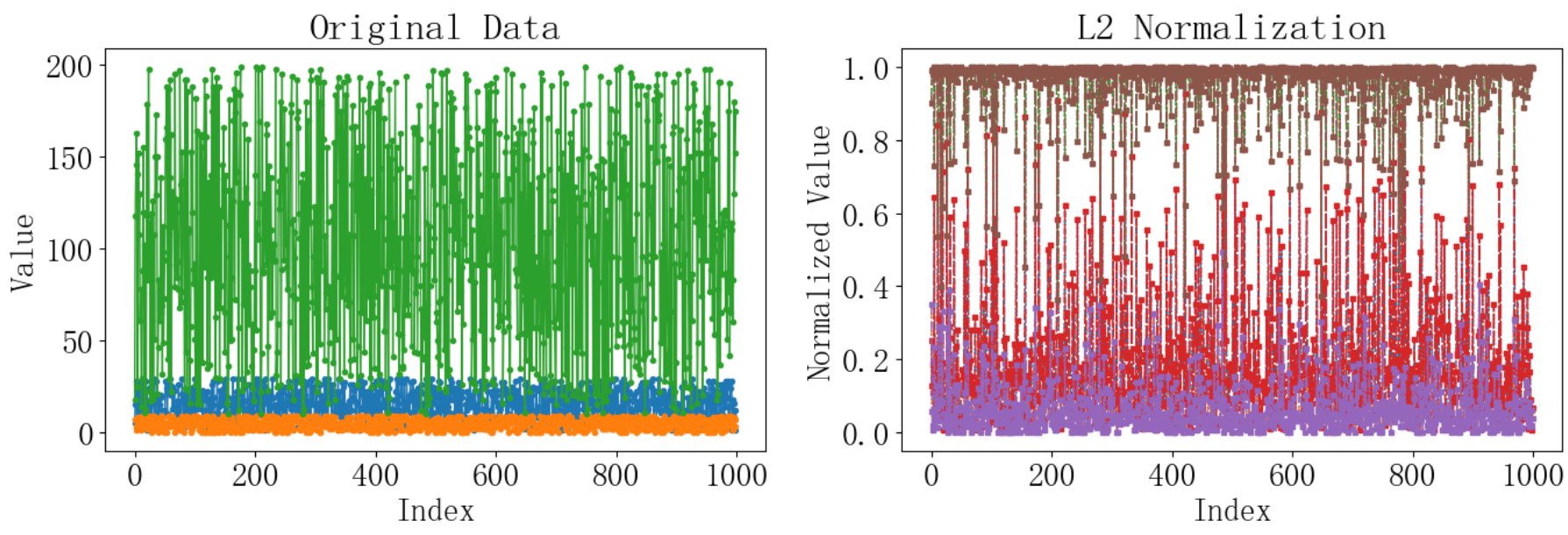
5 L2归一化
L2归一化,也称为欧几里得归一化或2-范数归一化,是一种将数据的特征向量按其平方和的平方根进行归一化的方法。其目的是将每个特征的平方和除以向量的欧几里得范数,使得每个特征向量的范数为1。L2归一化在许多机器学习算法中很有用,特别是在需要考虑距离度量时,例如在K近邻(KNN)算法中。
L2归一化的公式为:
![]()
其中:x 是原始数据向量,′x′ 是归一化后的数据向量。∑x2 是向量x中所有元素平方的总和。
L2归一化的优点包括:
- 它对数据的每个维度赋予了相等的重要性,因为它是基于向量的欧几里得距离。
- 它在处理需要考虑角度和方向的应用中有广泛的应用,如在图像识别和计算机视觉中。
示例程序将使用两种方法实现,自定义的L2归一化封装函数,并使用scikit-learn库中的Normalizer类作为第二种方法来实现归一化。以下是具体的实现:
方法1:自定义的L2归一化归一化封装函数
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import Normalizer
# 使用自定义函数进行L2归一化
def l2_normalization(data):
if isinstance(data, (pd.Series, pd.DataFrame)):
norms = np.sqrt(np.sum(data**2, axis=1))
data_normalized = data.div(norms, axis=0)
return data_normalized
else:
raise ValueError("Input data must be a pandas Series or DataFrame")
# 使用自定义函数进行L2归一化
data_normalized_custom = l2_normalization(data.iloc[:, 7:10])方法2: scikit-learn库中的Normalizer
# 使用 scikit-learn 的 Normalizer 进行L2归一化
normalizer = Normalizer(norm='l2')
data_normalized_sklearn_l2 = normalizer.fit_transform(data.iloc[:, 7:10])
data_normalized_sklearn_l2 = pd.DataFrame(data_normalized_sklearn_l2, columns=data.columns[7:10])
# 绘制原始数据和归一化数据的对比图
plt.figure(figsize=(14, 5))
plt.subplot(1, 2, 1)
# 绘制原始数据的线条图
for idx, col in enumerate(data.columns[7:10]):
plt.plot(data.index, data[col], label=f'Original {col}', marker='o', linewidth=1, markersize=3)
plt.title('Original Data')
plt.xlabel('Index')
plt.ylabel('Value')
plt.subplot(1, 2, 2)
# 绘制自定义L2归一化方法的数据的线条图
for idx, col in enumerate(data_normalized_custom.columns):
plt.plot(data.index, data_normalized_custom[col], linestyle='--', marker='x', linewidth=1, markersize=3)
# 绘制 scikit-learn L2归一化方法的数据的线条图
for idx, col in enumerate(data_normalized_sklearn_l2.columns):
plt.plot(data.index, data_normalized_sklearn_l2[col], linestyle='-.', marker='s', linewidth=1, markersize=3)
# 添加图例、标题和坐标轴标签
plt.title('L2 Normalization')
plt.xlabel('Index')
plt.ylabel('Normalized Value')
# 显示图形
plt.tight_layout()
plt.show()运行结果如下:
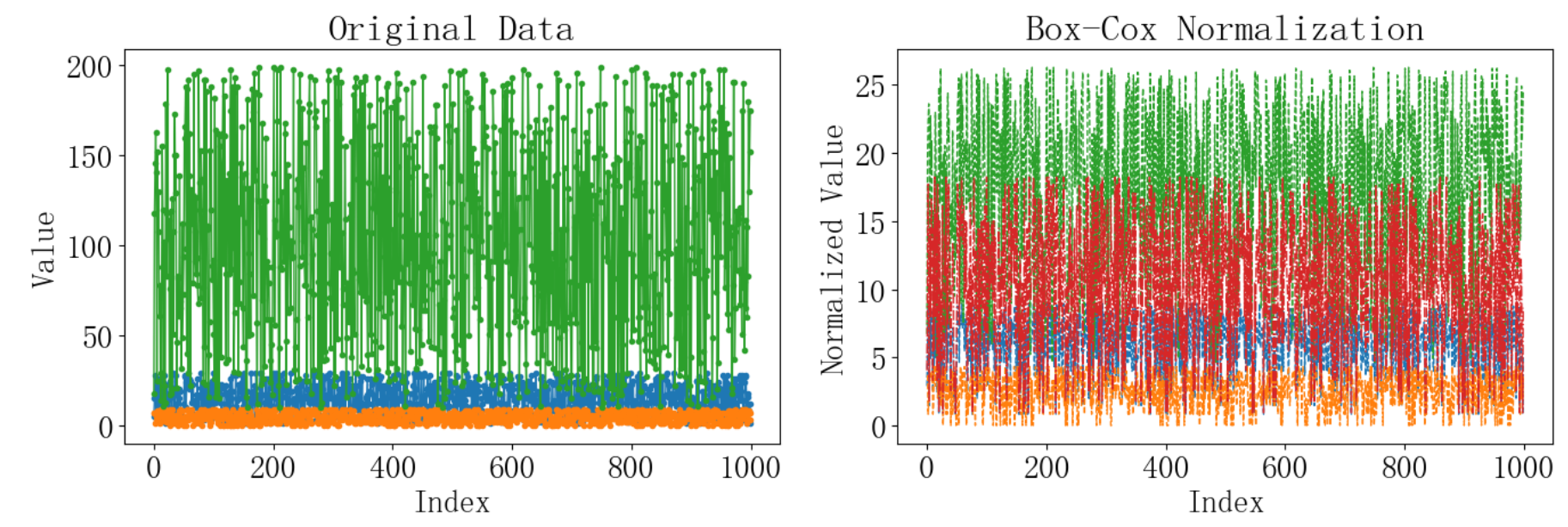
6 Box-Cox归一化
Box-Cox归一化是一种用于变换数据的分布,使其更接近正态分布的方法。它特别适用于处理具有偏态分布的数据,能够减少数据的偏斜性并稳定方差。Box-Cox变换是一种幂律变换,可以表示为:
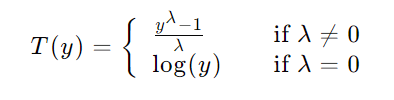
其中,y 是原始数据,λ 是变换参数。
Box-Cox归一化的关键步骤包括:
- 选择合适的变换参数 λ。这通常通过最大化变换后数据的似然函数来实现。
- 应用变换公式,根据选定的 λ 对数据进行变换。
Box-Cox归一化的优点包括:
- 它能够处理正值数据的偏态分布问题。
- 它可以减少数据的偏斜性,使数据更接近正态分布。
- 它可以稳定方差,使方差与均值无关。
示例程序将使用两种方法实现,自定义的L2归一化封装函数,并使用scipy的boxcox作为第二种方法来实现归一化。以下是具体的实现:
方法1:自定义的L2归一化归一化封装函数
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 自定义Box-Cox归一化函数
def custom_boxcox(data, lam):
if lam == 0:
return np.log(data)
else:
return (np.power(data, lam) - 1) / lam
# 选择Box-Cox变换的参数lambda,这里我们先假设为0.5(可以根据数据调整)
lambda_value = 0.5
# 为每一列分别使用自定义Box-Cox归一化函数
data_normalized_custom = pd.DataFrame()
for col_name in data.iloc[:, 7:10].columns:
data_col = data[col_name] + 1 # 确保数据为正数,这里加1进行平移
data_normalized_custom[col_name] = custom_boxcox(data_col, lambda_value)方法2: scipy库的boxcox
from scipy import stats
# 使用scipy的boxcox进行归一化
data_normalized_scipy, lambda_selected = stats.boxcox(data.iloc[:, 7] + 1)# 绘制原始数据和归一化数据的对比图
plt.figure(figsize=(14, 5))
plt.subplot(1, 2, 1)
# 绘制原始数据的线条图
for idx, col_name in enumerate(data.columns[7:10]):
plt.plot(data.index, data[col_name], marker='o', linewidth=1, markersize=3)
plt.title('Original Data')
plt.xlabel('Index')
plt.ylabel('Value')
plt.subplot(1, 2, 2)
# 绘制自定义Box-Cox归一化方法的数据的线条图
for idx, col_name in enumerate(data_normalized_custom.columns):
plt.plot(data.index, data_normalized_custom[col_name], linestyle='--', linewidth=1, markersize=3)
# 绘制scipy Box-Cox归一化方法的数据的线条图
plt.plot(data.index, data_normalized_scipy, linestyle='-.', linewidth=1, markersize=3)
# 添加图例、标题和坐标轴标签
plt.title('Box-Cox Normalization')
plt.xlabel('Index')
plt.ylabel('Normalized Value')
# 显示图形
plt.tight_layout()
plt.show()运行结果如下:
7 选择哪种归一化
各种归一化方法各有其特点和适用场景,以下是它们的使用场景和优缺点的对比:
| 归一化方法 | 特点 |
| Min-Max归一化 | 优点:可以指定数据变换后的范围。 缺点:对异常值敏感,因为最大值和最小值会受其影响。 |
| Z-score归一化 | 优点:降低了异常值的影响。 缺点:数据必须有明确的均值和方差。 |
| 最大值归一化 | 优点:可以处理非正态分布的数据。 缺点:对数据中的零值和负值不敏感,如果数据集中的最大值很少变化,可能导致归一化效果不佳。 |
| L1归一化 | 优点:能够产生稀疏表示,对异常值有一定的鲁棒性。 缺点:可能导致数据的某些特征被忽略,特别是当这些特征的绝对值较小时。 |
| L2归一化 | 优点:考虑了特征的相对大小,有助于保留数据的几何结构,常用于距离度量和聚类算法。 缺点:对异常值敏感,计算相对复杂。 |
| Box-Cox归一化 | 优点:可以处理正值数据的偏态分布,通过变换参数λ调整,可以找到最佳的数据分布。 缺点:需要选择合适的λ值,这可能需要多次尝试,对数据中的零值或负值不适用。 |